Hey, and welcome to the fourth update of the Brave New Teams newsletter.
Forget this world and all its troubles and if possible its multitudinous Charlatans – everything in short but the Enchantress of Numbers.

Ada Lovelace was an English mathematician and writer, chiefly known for her work on Charles Babbage’s proposed mechanical general-purpose computer, the Analytical Engine. She was the first to recognize that the machine had applications beyond pure calculation. She published the first algorithm intended to be carried out by such a machine. As a result, she is often regarded as the first computer programmer and the founder of scientific computing.
What happened?
During March, a lot of work went into improving the NLP-powered skills tagging and the team assembly algorithm. Those are the two key elements of the SuperScript value proposition (boxes 1 and 3 in the diagram below).
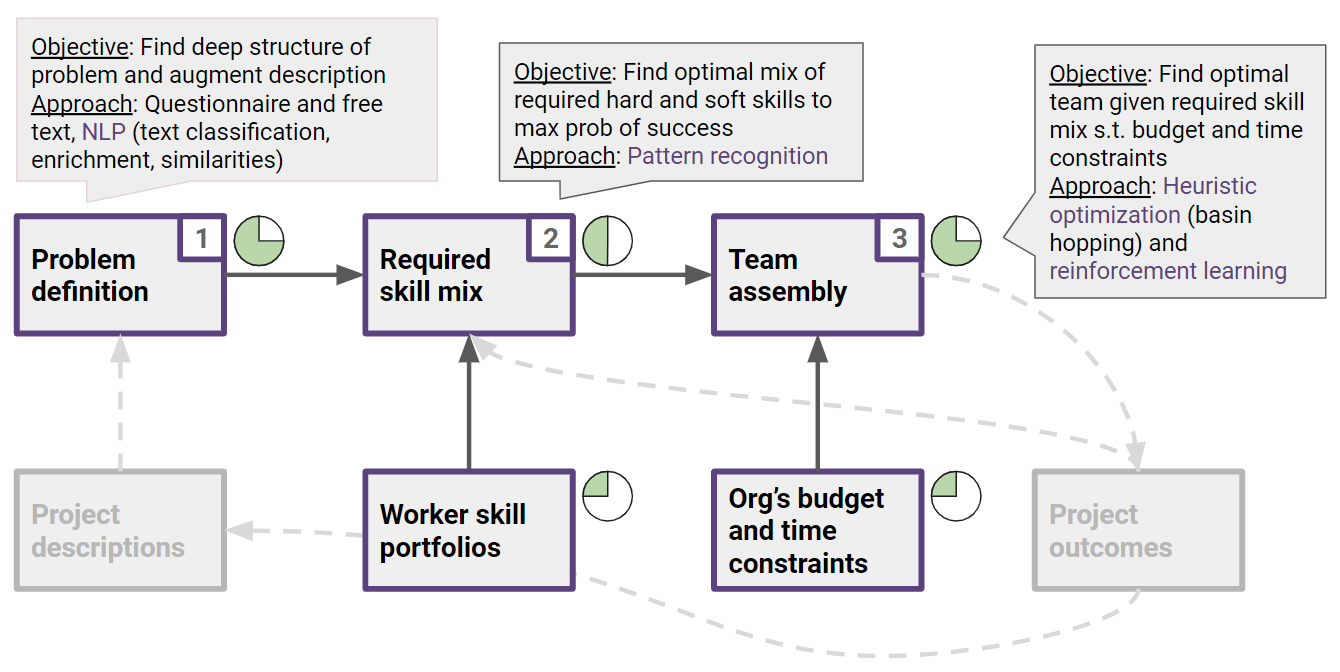
Team assembly model
We improved the agent-based model and added more visual comparisons. In the chart below, you see the impact on Return on Investment (ROI) of moving from a random team assembly mechanism (red line) to optimized versions of team assembly. The green line represents an optimal team assembly mechanism with a flexible start date (i.e., an option to wait for the right team members to become available) and no hard budgetary constraint (i.e., higher-skilled and thus more “expensive” talent can be added to the team). You can see that the ROI of the optimal strategy is more than twice as high as for the poor (“random”) strategy.
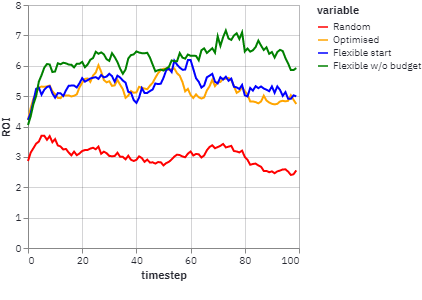
The agent-based model (ABM) is deployed as a Streamlit app to make it easy to run simulations and analyze data in your web browser (it works well on large screens and iPad, less so on a mobile phone). You can play around with the tool and change parameters yourselves.
Skills tagging tool
We use Natural Language Processing (NLP) to generate the relevant skills from a user-defined problem description. The skills are sourced from a proprietary skills hierarchy we have developed.
The skills tagging is done through a 3-stage process:
- The user enters a description of the tasks that need to be completed for the project. The description is in bullet point format with one task per bullet point.
- Skill categories are presented to the user, and the user confirms/selects the ones that are applicable to their project.
- Skills within each skills category selected in step 2 are presented to the user, and the user confirms/selects the skills that are applicable to their project. The skills presented in this step are organized by category and subcategory.
You can try out the prototype for skills tagging in your browser.
Two embedding models are used to search and rank categories and skills based on cosine similarity. When identifying categories relevant to a project, the category embedding model is used to generate embedding for a line of the project tasks description, and each of those embeddings is compared to every project category embedding using cosine similarity. The relevance level of a category to a project description is taken to be the highest cosine similarity between any line of the project description and any category. The same process is used to rank skills except using embeddings generated using a different model that is specialized for skills.
We employed various embedding models that were trained using transfer learning, starting with a pre-trained model and using a small dataset of tagged project descriptions to fine-tune the model. The ‘SentenceTransformers’ library was used, which is built on top of the Hugging Face library.
Why is it important?
Having working prototypes for the two key elements of SuperScript’s value proposition, the team assembly model and the skills tagging tool, is critical and a major milestone.
What’s next?
Now that the two key analytical pieces of SuperScript work, we will continue to make them better (more robust, faster, and hence “scalable”).
A critical part of this improvement effort is the introduction of Reinforcement Learning. Reinforcement Learning (RL) is “is a type of machine learning technique that enables an agent to learn in an interactive environment by trial and error using feedback from its own actions and experiences.” In the case of reinforcement learning, the goal is to find a suitable action model that would maximize the total cumulative reward of the agent. The figure below illustrates the action-reward feedback loop of a generic RL model.
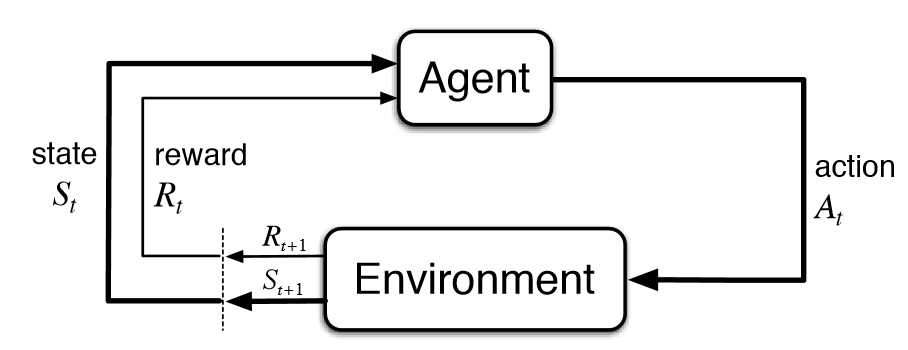
We have high hopes that RL can make the team assembly mechanism better (i.e., it converges faster to the global optimum). Most common applications of RL include resource management problems like job scheduling in compute clusters, which is similar in nature to the type of ‘logistics problem’ SuperScript is trying to solve.
In addition to improving the models, a focus, however, for the coming weeks is on connecting the two models and making them talk to one another. This is a technical piece of work but also one where the user flow, the interface, and the user experience must be thought through carefully and be designed.
On a side note: You may recall that we have launched a game (see here) in early 2022. The reception is way below expectations and we will be promoting the game over the coming weeks and months.
… one more thing
We promised to give an update on the Blockchain experiment. As I am sure you are aware, there is a lot of hype these days around web3, DAOs, and NFTs with a corresponding impact on the price of domain expertise. We, therefore, decided to go a bit slower about the Blockchain experiment that originally planned.
Endnote
Thank you for subscribing to Brave New Teams. There is a lot of talk about the future of work, the role of automation, and robots. But, as discussed in the post Automatic for the People, there is plenty of reason to remain optimistic about an augmented (and still human) future of knowledge work.
The next newsletter will introduce SuperScript’s user flow for an MVP, discuss the main use cases and give an update on the RL-approach for team assembly, the NLP-powered skills tagging, and their (technical) combination.
Stay safe, and don’t lose the script.Like this post
